微信群红包系统的设计
- 涉及知识点:
- 单个红包个数和并发量都有限,全网的红包数量和并发量很高;红包之间隔离性比较好
- 数据时效性明显,比较好做冷热数据
整体架构
###系统主要分为三层
- 接入层
- 业务层
- 数据层
主要的系统设计点
- 无效请求如何拦截
- 单个红包抢的人数有可能远远多于红包个数,所以需要对红包放行的请求做并发控制,可以采用redis descr操作
- 预生成红包,还是实时生成红包
- 两个方案都可以,大部分人会认为提前生成速度会更快,事实上提前生成需要持久化数据的操作成本,反而会更慢
- 负载均衡的策略是什么
- 在红包系统中,负载均衡的方式,直接决定了整个系统的架构;要合理利用红包之间良好的隔离性,采用红包id作为负载的key是关键;算法上,主要看是使用那种hash方式,一致性hash,range划分hash,还是hash取模,这里主要需要考虑数据层扩容和缩容时数据迁移的成本;微信采用的是末尾三位取模+range的方式,扩容时增加一个rangeid,缩容时,去掉一个rangeid即可;所以红包id的生成,末尾三位也是由业务来指定,指定的逻辑就是使用哪个存储单元
- 抢红包串行处理还是并发处理
- 这里主要考虑数据一致性的问题,解决一致性并发环境下,可以使用事务,缺点是事务概率冲突比较高,会严重影响业务处理性能;乐观锁失败的概率比较高会影响用户体验;也可以使用分布式锁,缺点是并发过高锁资源会成为热点;如果业务保证串行化处理,可以有效减少事务冲突,事务本身更多是用于保证业务处理的完整性;
- 红包入账怎么设计
- 红包金额的入账并不影响整个红包业务的体验,用户也不会立马去关注余额是否入账;这里可以采用MQ,异步的进行入账处理,可以有效消峰,平滑处理
- 数据量的考虑,分库分表的如何设计
- 红包业务并发量、数据量很大,增长也很快,业务隔离性也比较好;分库分表可以有效的提高业务的并发性,由于业务的特点,数据有效性时间比较短,可以比较好的做冷热数据的迁移;避免单表数据量过大导致性能下降的问题;分库分表的设计,需要考虑长期的时间因素,也需要考虑短期表拆分;所以比较好的方式是,不同rangeid做库级别的分离;同一库中的,使用日期作为表的元素
- 冷热数据的考虑
- 定期做数据迁移,保证业务数据库中只保留最近的红包业务数据热数据,可以有效的降低磁盘的压力
- 隔离方案,容错方案
- 如果摸个数据单元由于压力过大出现失败的,业务上可以重试其他的存储单元,通过指定红包系统id上的存储单元id,做到平滑的容错
通过标准
- P7技术专家,技术经理:
- 在不提示的情况下,对红包系统的特点有比较好的认识,能够认识到整体的并发量高,单个红包的并发量低;能够想到红包id作为负载均衡的key,在单个红包的并发处理上,能够想到并发控制的多种方案,例如分布式锁,分布式事务,mysql事务来保证红包的业务的数据一致性,适当提示这种方案可能存在的系统瓶颈,如何化解;或者可以采用设计请求队列的方式,将红包业务串行化处理;最好能够阐述各种方案的有缺点;在数据层的建设上,能够阐述清楚表的结构,包含红包信息表和红包记录表,这块适当提示下,能够对分库分表方案做合理的设计,至少体现时间的维度;在架构设计上,能够体现三层的设计架构,分清计入层、业务层和数据层的概念;数据一致性上,不能因为并发量高,把redis当成db来使用,然后异步同步到db,而忽视缓存出问题后数据丢失的问题;合理使用redis作为并发控制(无效请求拦截),红包详情数据加速;在分库分表的方案上,可以深挖一下,看候选人是如何来看待分库和分表的设计,如果能体现冷热数据分离,读写分离,表结构的垂直切分,区分核心数据和其他数据等设计的点,可以体现出有丰富的数据库设计经验;如果是现场面试,可以要求表结构的设计。从面试的经验来看来看,候选人的方案会多种多样,总体的思路是看候选人给的方案是否能自圆其说,合理评估,并且在讨论和探讨后能让你感到满意;
- P6资深工程师:
- 在业务的认识上,需要和P7一致;对并发性和数据一致性有比较好的认识,所以在负载均衡上,需要在设计上能够体现,至少能够使用MQ或者redis的list做为请求队列来消峰和串行化处理的方案,并发控制上,对无效请求做拦截;另外,对数据库的设计,需要更加详尽,可以要求对表结构进行设计,整体的架构层次也能分清;其他的点,在引导下,能够往P7的方向上靠,比如分库分表方案。
- P5高级工程师
- 能够对业务进行梳理,重点可以放在详细的设计细节上,而不是整体架构上;可以给出设计方向的提示,让候选人沿着这个方向去思考并给出结论;比如在负载均衡上,应该如何来做,可以让他去思考;在并发控制上,应该如何来做,在数据库设计上,应该如何来做,才能提高并发性;如果采用redis作为主要数据存储方案,异步写入db,方案比较完整(比如加入了事务补偿,对账环节)也ok;总体的方向就是能够有比较好的业务敏锐性,同时思维较活跃。
- P4中级工程师
- 主要还是看对业务的理解来看他未来的潜力,思路和P5类似,给方向,让候选人思考,重点考察思维反应和知识面;
限流服务设计
- 涉及知识点:
- 分布式系统基础
- 并发控制设计
- 数据分片
- 限流算法设计
- 数据一致性分析
- 数据库、缓存、局部内存保护
设计背景
可以解决哪些场景下遇到的问题?
- 客户端的异常代码或恶意用户高频刷接口
- 安全性:暴力试错破解密码
- SaaS 服务多租户限流
- 限制开发者使用 API 的方式
- …
设计要求
- 功能要求
- 在一段时间窗口内限制每个用户访问某个 API 的次数不超过某阈值
- 限流服务本身处于云原生环境,支持横向扩容,因此需要支持跨实例限流 (分布式限流)
- 性能要求
- 1000 万用户,最大时间窗口为 1 小时,假设每小时某用户访问某个 API 的平均数量为 500
- 低延迟:99 时延分位在 10ms 以内,越短越好
- 高可用,数据一致性要求低,可以容忍少量限流不准确,不接受大面积数据丢失
主要的系统设计点
- 不同的限流算法设计及其优劣分析
- 固定窗口 (Leaky Bucket/Token Bucket):逻辑简单,存储空间占用小,限流不准确
- 滑动窗口:不同滑动窗口策略,空间、效率权衡
- 成本预估:能根据给定用户量、访问量正确估算存储成本
- 数据量考量:
- 对数据分片 (缓存和磁盘),不同分片策略的好坏、扩容缩容对分片的影响
- 数据压缩:key 压缩、时间戳压缩
- 垃圾收集:数据时效性
- 限流单元分析:以不同属性作为限流单元有什么区别?
- UserID:注册用户有稳定的 uid,那么用户注册 API 本身如何限流?
- IP:共享同一个公网 ip 的用户群体可能互相影响;ipv6 数量众多,可能把存储搞垮
- DeviceID:一个用户可以使用多个设备登录,影响限流准确性,数据量也比 UserID 大
- 复合限流单元:如 UserID 限流 + IP 限流,牺牲空间
- 超载控制分析:限流服务本身超载怎么办?接口分类定级,按优先级降级;分析热点,单点降级
- 监控指标分析:
- 服务本身的成功率、时延、QPS
- 不同实例间的负载均衡情况:cpu, goroutine 等
- 被限流与通过的比例:帮助分析限流服务本身的作用、API 维护者了解接口超限情况等
评价标准参考
以下提供一些参考点,但不限于此,可以临场根据情况讨论其它方面问题,只要候选人给的方案能自圆其说,并且在讨论和探讨的过程中让你觉得满意即可。
- P7
- 迅速理解系统背景和应用场景,缩小问题,拟定架构
- 能够提出并对比不同限流算法的优劣;理解不同算法在空间、准确度上的权衡
- 能够正确预估系统占用的资源,主要是存储资源
- 有多种解决数据量大的方案,包括但不限于分片、压缩、垃圾收集
- 能理解不同限流单元选择可能解决和带来的问题
- 有服务容错考量,能考虑到限流服务本身出问题的不同情况,有应对措施
- 能确定合理的监控指标并描述指标的不同趋势可能显示的问题
- P6
- 迅速理解系统背景和应用场景,缩小问题,拟定架构
- 能够提出并对比不同限流算法的优劣;理解不同算法在空间、准确度上的权衡
- 有一种解决数据量大的方案,包括但不限于分片、压缩、垃圾收集
- 有服务可用性意识,能考虑到服务本身可能出问题的情况
- 能理解监控的重要性,并能描述监控对系统改进的反馈作用,能提出一些基本指标
- P4、P5
- 能够提出并对比不同限流算法的优劣;理解不同算法在空间、准确度上的权衡
- 有一种解决数据量大的方案,包括但不限于分片、压缩、垃圾收集
- 有服务可用性意识,能考虑到服务本身可能出问题的情况
详细设计要点
架构设计
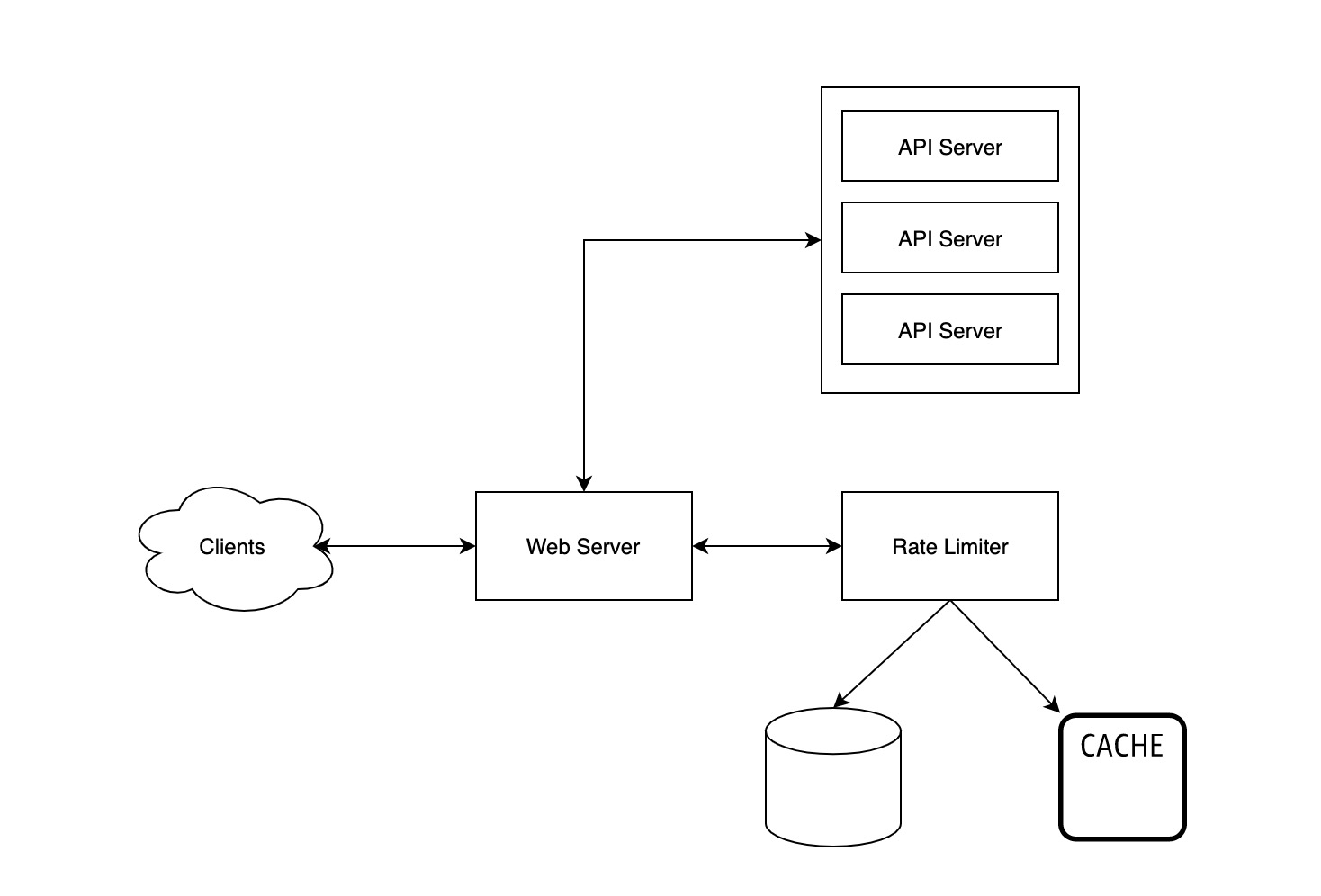
接口设计
1 | type RateLimitingReq struct { |
限流算法
Leaky Bucket/Token Bucket
漏斗/令牌桶算法
分析点
- 令牌桶算法的优劣分析
- 突发流量可能让后续流量饿死
- 处理请求的时间可能不等
- 内部队列削峰填谷
Fixed Window Algorithm
1 | Key : Value |
- 如果
UserID不在哈希表中,插入相应 Value,其中 Count 为 1,StartTime 为最近一个时间窗口的起点 - 如果
UserID在哈希表中CurrentTime - StartTime >= WindowSize,更新 StartTime 为最近一个时间窗口起点,Count 置为 1CurrentTime - StartTime < WindowSize- 如果
Count < Threshold,Count 自增 1 - 如果
Count >= Threshold,拒绝请求
- 如果
分析点:
- 限流准确性问题
Sliding Window Algorithm
滑动窗口限流算法,解决固定窗口限流准确性问题
Variant 1: raw timestamps
用 SortedSet:
1 | Key : Vaue |
- 从 SortedSet 中删除所有一个时间窗口之前的数据
- 计算 SortedSet 中的元素数量
- 超过阈值,拒绝请求
- 未超过阈值,往 SortedSet 中插入时间戳
分析点
- 与固定窗口相比,用空间换准确性
- 单条数据占用空间大,如何解决扩展性问题?
Variant 2: with counters
结合 Variant 1 和固定窗口,将时间窗口划分成小的固定窗口,取二者所长。
Variant 3: moving average
改进固定窗口,对前后两个窗口取加权平均,假设窗口 1 的调用量是 100,窗口 2 刚推进了 20%,调用量为 10,那么此时计算公式为:Window1.Count * 0.8 + Window2.Count * 0.2。
存储成本预估
Fixed Window
假设:
- UserID 8 字节
- Counter 2 字节 (65536,足够)
- 时间戳 4 字节 (可优化)
总共:
1 | 8 + 2 + 4 = 14B |
用户量为 1000W:
1 | 10000000 * 14B = 130MB |
细化:
- 考虑时间窗口内活跃用户的比例
- 考虑多个 API(以上计算仅考虑了单个 API 的情况)
Sliding Window Variant1
假设:
- SortedSet 每个元素的额外成本为 20 字节
- 时间戳 4 字节
- UserID 8 字节
- HashTable 的额外成本为 20 字节
总共:
1 | 8 + (4 + 20) * 500 + 20 = 12KB |
用户量为 1000W:
1 | 10000000 * 12KB = 114 GB |
数据分片、数据缓冲、数据一致性
- 数据分片
- 用
UserID作为 Hash Key 对数据分片,使用一致性哈希尽量保证 session stickiness。(有没别的数据分片方案?) - 用号段分片,参考微信红包方案,这时候各个分片中的 key 的长度可以进一步缩短
- 限流数据根据时间窗口长度分类,比较短的可以不落盘
- 用
- 扩容过程,如何平滑扩容
- 将缓存中间件作为 write-back cache,数据定期同步,扩容时预热缓存
- 所有的方案都基于
read-and-modify,实际上是写偏斜 (write-skew),有什么解决方案?lua scriptmodify-and-read
参考
- Kong: How to Design a Scalable Rate Limiting Algorithm
- High-performance rate limiting
- An alternative approach to rate limiting
- Grokking the System Design Interview: Designing an API Rate Limiter
排行榜系统
- 涉及知识点:
- 性能优化
- 热点分析
- 数据分片
- 数据结构, 缓存设计
需求
设计一个排行榜系统
可以查询出 每天/月/年/总榜 每个用户获得的奖励(贝壳)排行榜
以及当前用户在排行榜上的名次
设计要求
- 可以查询每个用户当前的排名
- 排行榜更新时效性保证分钟级别更新
- top N (N < 1000) 要做到实时更新
性能要求
- 千万量级用户, 峰值 QPS > 1万
- 读写延迟低于100ms
- 高可用(服务实例/存储实例宕机场景分析)
参考架构
数据库设计
1 | CREATE TABLE board_bucket_$id ( |
redis 设计
一个 bucket 对应一个 sorted-set
查询逻辑
查询用户当前所在桶中的排名, 加上所有小于用户当前桶的桶大小, 即为用户当前排名
1 | func QueryRank(uid int64) int64 { |
更新逻辑
用户分数更新后, 查询自己所在的桶
- 在同一个桶中, 那么只需要更新桶中分数
- 更新后跨桶, 更新用户对应桶, 删除旧桶数据, 将数据写入新桶
数据重做逻辑
- 计算每个bucket对应的 score 范围后, 将用户 rebalance 到对应 bucket. 更新量不大于用户量
设计点
直接查询排名涉及到全局排序,如何设计存储来规避这个问题.
- 采用分桶策略, 根据排行榜数据分布分桶,或者根据用户数据量分桶. 这块可以开放来回答, 言之有理即可
关于内存缓存
- 需要缓存各个 bucket 的大小,以及 score 区间. 便于查询加速
用户数据更新
- 可以考虑多种方案(MQ, 合并写, 定期 rebalance 等, 根据场景选择)
redis 或者 DB 宕机如何处理
- 如果 DB 宕机, 需要保存写请求到 MQ,等待恢复后重放
- 如果 redis 宕机, 系统降级 rank 的查询
- 根据线性插值法估算排名(这块可以有很多近似估计法, 根据情况要求候选人回答)
- rank = (max_score - user_score) * bucket_size / (max_score - min_score)
Top N 热点数据如何缓存, 如何保证强一致性
- 针对 Top 可以设立单独的缓存或者存储, 用户数据更新如果进入 Top N 的范围, 需要重建缓存, 这块需要单独讲清楚
通过标准
P7 技术专家
- 对于整个系统需要解决的问题, 有比较清晰的认识. 能够想到分桶或者其他类分治的方法.
- 对于热点查询(Top N)能想到缓存的方案, 以及强一致性的方法, 思路不能有模糊的地方
- 在鲁棒性上, 对于 db 宕机, 以及峰值写入, 并发查询的场景需要能给出正确思路
- 对于降级以及容灾方案,需要讲清楚流程
- 分桶设计以及数据更新流程上, 需要讲清楚每一步的细节.
- 需要考虑服务通用性设计, 而不是针对单一的场景
P6 资深工程师
- 需要考虑到分桶的设计,如果没想到分桶设计, 也需要提供近似估计的一些方案(全局近似估计)
- 对于热点数据, 需要考虑查询效率的问题
- 数据库以及缓存的结构设计需要讲清楚原因
- 能给出一些性能以及稳定性相关的优化方案(结合具体场景)
P4/5
- 给提示的基础上, 能够按照提示给出设计思路和细节
- 对于性能问题, 可以把数据量降低到百万级别进行考察,需要给出一些优化方案
- 对于服务的一些潜在问题, 能提出并自主给出解决方案
参考
- https://cloud.google.com/datastore/docs/articles/fast-and-reliable-ranking-in-datastore#howtorank
- https://yq.aliyun.com/articles/280998
- https://www.infoq.cn/article/tencent-ranking-system-practice-and-challenges
团购服务设计
- 涉及知识点:
- 业务理解能力
- 数据结构设计
- 并发控制设计
- 数据一致性
- 异步化处理
- 数据分库分表
模拟一个实际场景的需求,实现一个团购业务系统,随着需求变更,考查候选人调整选型和系统设计以及问题解决能力
需求描述
面试官作为产品,提出以下业务需求:
- 实现一个简化版团购
- 用户选择某个商品发起团购,一个团有人数限制,有时间限制
- 其他用户点击分享的团购链接参与团购
- 团购人数满额则状态变为成团
- 两个约束条件:
- 每个人每个团只能参与一次(不重)
- 每个团有人数限制,不能超限(不超)
- 核心接口:开团,参团
- 开团参团不需要支付
- 基于以上需求,设计一个团购系统,描述数据结构设计,存储选型,核心接口实现逻辑等
基础设计
基础设计方案:
- 选择mysql数据库,表结构(团表,参团表),有些还会提到商品信息表等,核心还是前两个
- 表关键字段
- 团表:团id,开团人,团状态,团人数,时间戳,商品id等
- 参团表:团id,参团人,角色(团长 or 团员),时间戳 等
- 团表、参团表 1对多关系
- 开团逻辑:
- 库存判断,活动时间判断等
- 写入团表,写入参团表(团长角色)
- 参团逻辑:
- 根据团id,行锁-锁团表记录
- 判断约束条件,写入参团表
- 判断成团条件,成团改变状态
- 但是这种方案,参团是串行模式,性能并不高
- 约束性如何实现(不使用行锁)
- 不重:
- 参团表对团id,参团人建唯一索引(后置模式)
- 或者使用redis,以团id为key,参团人存set里,保证原子性
- 不超:
- 开团时redis设置库存,参团时扣减(结合不重的redis方案)
- 可以结合着需求来挖掘候选人对问题理解,这里的约束性需要保证操作原子性
- 不重:
其他设计方案:
- 选择使用redis + mq + mysql 方案
- 开团写入redis list,每个元素是一个参团资格
- 参团时list pop,约束性条件可以用上面基于redis的方案
- 开团参团操作通过mq,同步到mysql持久化&后续统计使用
- 追问:redis和mysql如何保持数据一致性? – 如何设计检查与补偿机制
需求变更1
- 开团,参团需要支付,支付可以走微信支付,充值后扣款,也可以直接走账户扣款
- 考察点:分布式事务,一致性保证
- 方案:
- 如果候选人有支付系统相关经验,可以了解下支付回调后,业务执行操作失败退款和重试机制(基于mq实现)
- 如果不走支付,直接走余额扣款(如钱包),引入分布式事务处理:
- tcc方式:钱包,团购服务 需要支持tcc语义,改造会比较大
- 基于mq消息通知:先扣款,成功后写消息,异步开团/参团,用户交互需要配合修改
- 事务补偿:类saga方式,先扣款,后开团/参团,若失败回补扣款(幂等id),可以由团购服务作为协调者
- 不同实现方式,开发成本,一致性保障都会有差异,要结合实际情况来使用
需求变更2
- 系统上线一段时间之后,数据量变大,导致操作很慢,优化方案?
- 考察点:分库分表,冷热分离,新NewSQL了解
- 方案:
- 分库分表的方案:
- 按团id分,团记录和参团记录都在一个分区上,支持同一个团内事务
- 可以追加需求:用户如何查看自己所有参团记录?
- 扫所有表? – 成本较高
- 或者记录用户-参团 关系表,按用户uid分表
- 冷热数据方案
- 由于团购数据具有时效性,可以做冷热分离
- 进行中的团基本都是热点数据,和已结束团按团的时间拆分存储
- 使用TiDB方案
- 用团id作为主键,自动拆分
- 分库分表的方案:
需求变更3
直播万人团
该服务上线后,我们邀请了李佳琦来做直播,由李佳琦开团,团人数为一万人,由李佳琦直播倒数大家一起来参团,由于优惠力度很大,需要控制好数量,且满足上面两个约束条件。
设计方案:
- 此时候选人需要意识到这个不是单纯的团购,而是抢购场景(与普通抢红包不同,是全局热点资源抢购),基础方案不适用,所以设计要重新考虑(参考)
- 设计点需要解决的问题:并发流量控制,约束条件的实现,抢购系统和业务系统解耦
- 抢购方案 – 基于redis集群
- 以uid为key,分流到N个桶,构造N个 redis set判断是否抢购过 – 解决不重
- 将1w个token资格,提前存入到M个redis list,通过pop获取token – 解决不超
- 通过路由规则到某个存token redis list,抢到token后,通过mq异步写入数据库
- N 和 M的数量可以根据预计流量评估,分流到多个分片中,预估每个分片请求量不超限制
- 稳定性保障:
- 每个服务实例要做上游限流(排队)
- 抢购方案 – 基于放号器
- 服务分为front_service,token_service
- front_service 负责抗流量,通过路由规则同一个uid分流到同一个front_service上
- front_servcie 维护 map<uid, token> 记录该用户是否抢到token
- token_service 按一定速率将token写入redis list,由front_service拉取(先到先得)
- front_service 获取token后随机分给某个map中的uid
- token_service 放号结束通知front_service
- 不重:同一个uid同一个map
- 不超:token服务控制数量
- 该方案还可以挖掘一些细节:比如抢购过程中token_service挂掉怎么办等等
- 抢购方案 – 预存模式
- 如果流量非常极端(如春晚模式),可以用类cdn模式
- 提前预算不同地域流量,按地域权重分配token,通过文件分发到各地区机房
- 路由规则直接打到本地接入点,抢到token后才请求主机房,由主机房做核心逻辑
- 核心思想是将主要流量分发到各区域,只有核心逻辑回流主机房
设计点
- 可以根据候选人情况,先从基础版的团购开始,逐步调整需求和提升难度,看候选人的设计变化,选型,背后的思考。没有方案是完美的,但是可以从方案中看出思路。
通过标准
P7技术专家:
- 不提示下,至少能完成基础版的设计方案,不重,不超的约束条件要满足,而且知道性能上不足。可以顺着需求,提出需求变更1,2,3,分别对应不同的挑战点(分布式事务,分库分表方案,抢购场景),在分布式事务,分库分表上要较好回答,能提出一些解决方案,抢购场景作为开放性问题,看看候选人思路和理解能力,至少能提出一种解决方案,选型的原因,优缺点,即使不完美也至少知道存在的不足,以及可能的解决方向。
P6资深工程师:
- 业务理解正确,在不提示下,能完成基础版设计方案,实现逻辑,约束条件满足都要达到要求。对并发性有一定认知,在需求变更1,2上能回答出来解决方案,能满足业务需求,抢购场景有一定思路,可以在引导下提出一种解决方案,能对比方案优缺点。
P5高级工程师:
- 业务能理解清楚,完成基础版设计方案,结构,实现逻辑,约束条件能大体上达到要求,可以做一定引导。对于较好的P5可以展开变更需求1,2,甚至3,看看其思路,不一定需要完整方案,但是可以了解候选人知识面广度,对问题的理解与认知。
P4中级工程师:
- 主要是看对业务理解,可以在引导下做基础版方案设计,给方向看看候选人思维能力,理解能力,知识面等等,以判断潜力为主。
预约推送功能设计
- 涉及知识点:
- 生产者消费者模型
- 数据分库分表/冷热分离
- 错误重试机制
- 系统监控设计
- 限流机制
- 幂等控制
业务需求
- 产品需求:
- 用户在活动页面上点击预约某产品/活动,也可以取消预约
- 在某个时间点以前,对所有预约某个产品用户批量发送推送
- 系统需求:
- 预约用户在千万级左右
- 推送接口每次只能发1000个用户,单次耗时200ms,且可用性只有99%
- 推送时间要控制30分钟内
- 要避免给用户重复发push
主要设计点
- 预约数据如何存储
- 如何做选型以支持预约/取消预约功能,以及发送时能快速读取数据
- 这里的难点在于既要支持快速在线读取/修改,也要能支持按预约产品批量导出
- 如果选型只用MySQL的方式实现,导数据时就需要一些实现技巧,比如按产品分表,读取数据时用时间戳或者主键分段读取,控制每次读取数据量
- 如果选型用MySQL+redis的方式实现,则针对每个产品,同时用zset存储uid,读取时按顺序读取批量uid,如果单zset过大,可以分到多个zset来存储
- 如果选型用类似HBase的kv存储,则可以用pid+uid的key来存储,此时同一个产品预约数据都在相邻key,直接按序scan
- 也可以用MySQL存储,添加/修改数据同步到hadoop,导出时跑任务导入到MQ,消费MQ数据
- 做法很多,不同选型有不同的实现方式,有对应的优缺点和取舍,但是可以通过这个方式了解到候选人的知识面,对问题理解,选型的过程,处理细节和取舍等等
- 如何支持快速批量发送
- 生产消费者模型,生产者从数据源按每批次拉取数据,存入队列(MQ,redis,channel等);消费者起多线程/多协程/多进程读取队列消费数据,并往push服务发送推送
- 如果是回答用Go channel来实现,可以进一步问go的并发编程模式,如何利用channel协同生产消费者
- 如何控制发送速率
- 由于下游推送接口容量有限,要使用一定限流控制方法,避免把下游打挂
- 可以简单限制消费者并发量,但是并不能做到太精准
- 可以用一般限流算法:固定窗口/滑动窗口,原理?
- 可以用:令牌桶/漏桶算法,原理?
- 如果消费者是多实例下,分布式限流怎么做:redis单key OR 定期上报,实现方法的取舍
- 此处看候选人对问题理解,按不同方法展开问实现方法和细节,包括思路和取舍原因
- 失败重试机制
- 下游可用性99%,有1%的失败请求需要重试
- 失败的请求可以放重试队列,设置一定delay时间,按失败次数递增delay时间,有最大重试次数,并检查deadline时间(超过发送push时间点)
- 不同的delay重试时间,如何维护?SortSet结构(延迟队列)
- 避免给用户重复发push
- 幂等设计,按每批次所有uid和任务id hash成token,发送检查token
- 更进一步(如果不同批次有相同uid),按单个uid和任务id做token来检查,但影响发送性能
- 业务思考能力
- 产品经理点击发送之后,不知道什么时候能发完,此时怎么优化系统?
- 提供进度查询功能,发送任务开始时,快速评估发送总量,生产者,消费者将处理数据上报,及失败数据,提供页面展示
- 作为开发者,该功能需要关注哪些指标?发送速率?失败率?平均发送耗时?
- 其他点按候选人的想法进行讨论,可以了解到候选人对功能更多的思考
评价标准参考
P7
- 能快速理解需求,并能根据实际情况设计方案,能讲出存储选型原因,取舍的原因,各自有什么问题
- 能提出生产消费者模型,并根据并发量需求,给出不同处理方法,若有Go开发经验,能清晰描述不同并发编程模式
- 能给出不同限流方案,并理解其原理,理解不同方案的优缺点
- 失败重试机制,能考虑到多次失败的处理方法,能考虑到类似延迟队列的处理方法
- 能考虑到整个逻辑过程中可能会出现问题的环节,并考虑到解决方案
- 在不明显提醒下,有系统风险意识,能提出功能的关键指标,监控指标有意识,知道如何评估结果
- 业务思考方面有多种思路,可以针对实际情况,扮演产品经理,对需求做一些变更,看候选人能根据需求情况灵活变化
- 此级别主要关注其设计背后思路,对功能风险点的理解,面对业务的变动如何做取舍,以及对业务的进一步思考
P6
- 能根据需求设计对应方案,能解决问题,但是有自己想法,知道不足
- 能知道生产消费者模型,如何应用到业务中
- 有系统可用性意识,能提出多种限流方法,以及重试策略,并知道其优劣点
- 知道幂等在一些关键业务中的作用,以及如何使用之
- 对业务指标有一定理解,并提出几个需监控关键指标,并提出如何实现监控
- 此级别主要关注其设计与实现,能理解不同实现之间的差异,有一定风险意识,对业务也有一定思考
P5 P4
- 能根据需求给出一种解决方案,能说出选型原因
- 了解生产消费者模型,以及应用在这个需求上的方法
- 知道限流的多种方法,并能理解其不同点
- 能至少提出2个关键指标,有服务可用性意识,一定程度了解系统风险点

