互斥锁Mutex
说起并发访问问题,真是太常见了,比如多个 goroutine 并发更新同一个资源,像计数器;同时更新用户的账户信息;秒杀系统;往同一个 buffer 中并发写入数据等等。如果没有互斥控制,就会出现一些异常情况,比如计数器的计数不准确、用户的账户可能出现透支、秒杀系统出现超卖、buffer 中的数据混乱,等等,后果都很严重。
这些问题怎么解决呢?对,用互斥锁,那在 Go 语言里,就是 Mutex。
临界区:在并发编程中,如果程序中的一部分会被并发访问或修改,那么,为了避免并发访问导致的意想不到的结果,这部分程序需要被保护起来,这部分被保护起来的程序,就叫做临界区。
如果很多线程同步访问临界区,就会造成访问或操作错误,这当然不是我们希望看到的结果。所以,我们可以使用互斥锁,限定临界区只能同时由一个线程持有。
Mutex 的架构演进分成了四个阶段: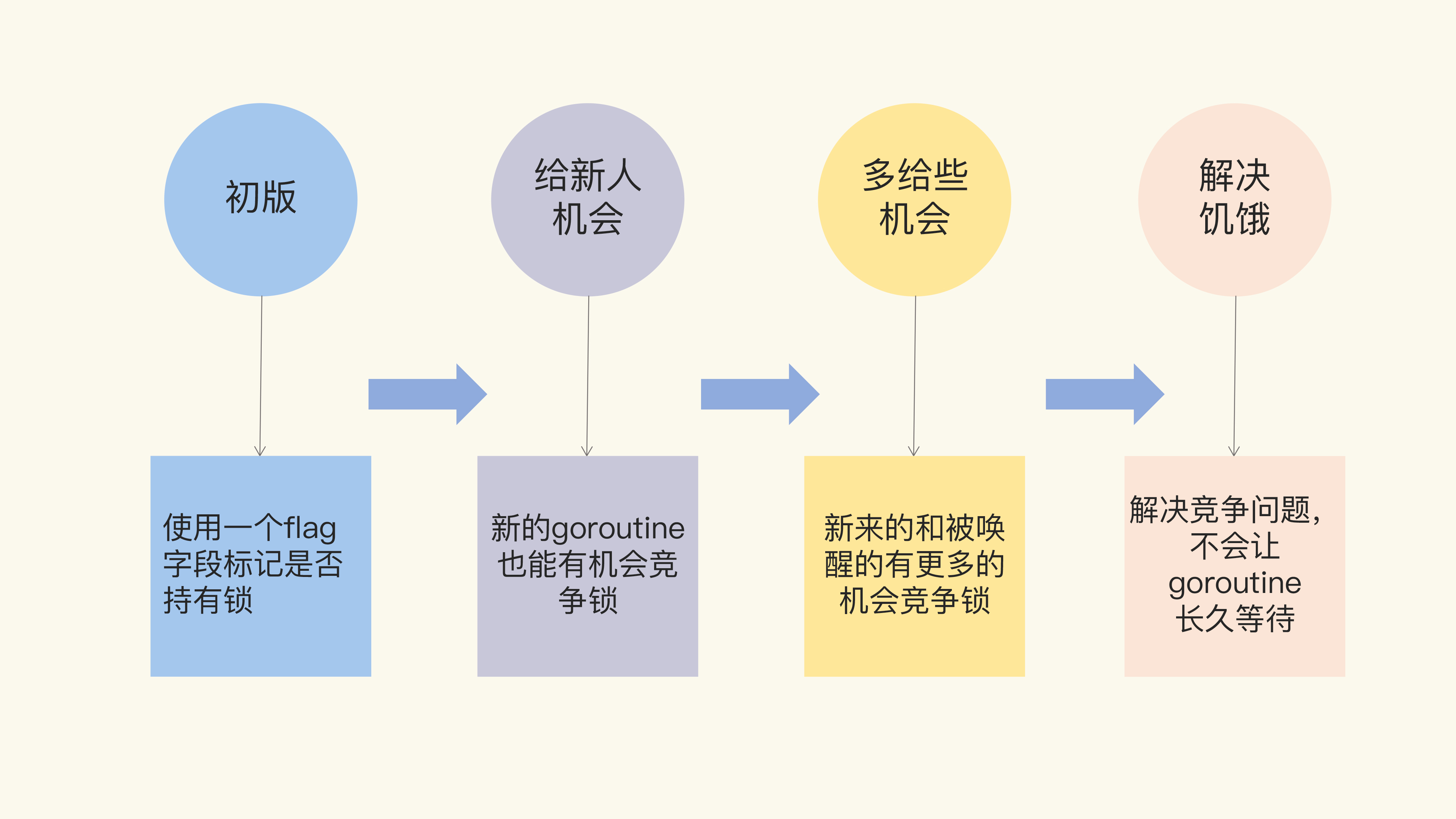
互斥锁1.0
通过一个 flag 变量,标记当前的锁是否被某个 goroutine 持有。如果 这个 flag 的值是 1,就代表锁已经被持有,那么,其它竞争的 goroutine 只能等待;如果 这个 flag 的值是 0,就可以通过 CAS(compare-and-swap,或者 compare-and-set) 将这个 flag 设置为 1,标识锁被当前的这个 goroutine 持有了。
1 | // CAS操作,当时还没有抽象出atomic包 |
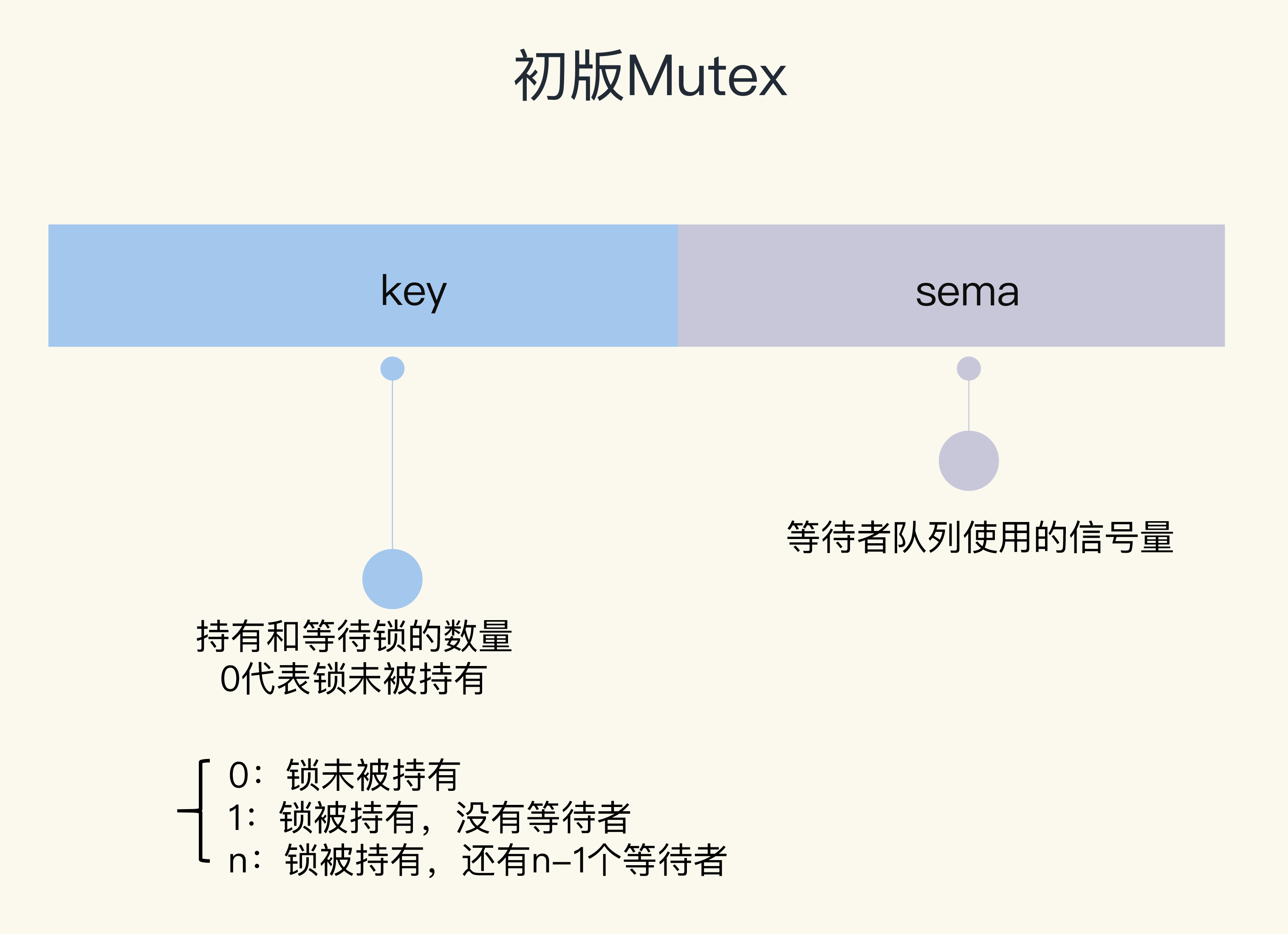
Unlock 方法可以被任意的 goroutine 调用释放锁,即使是没持有这个互斥锁的 goroutine,也可以进行这个操作。这是因为,Mutex 本身并没有包含持有这把锁的 goroutine 的信息,所以,Unlock 也不会对此进行检查。Mutex 的这个设计一直保持至今。
所以,我们在使用 Mutex 的时候,必须要保证 goroutine 尽可能不去释放自己未持有的 锁,一定要遵循谁申请,谁释放的原则。
但是,初版的 Mutex 实现有一个问题:
请求锁的 goroutine 会排队等待获取互斥锁。虽然这貌似很公平,但是从性能上来看,却不是最优的。因为如果我们能够把锁交给正在占 用 CPU 时间片的 goroutine 的话,那就不需要做上下文的切换,在高并发的情况下,可能会有更好的性能。
互斥锁2.0:给新人机会
1 | type Mutex struct { |
虽然 Mutex 结构体还是包含两个字段,但是第一个字段已经改成了 state,它的含义也不 一样了。
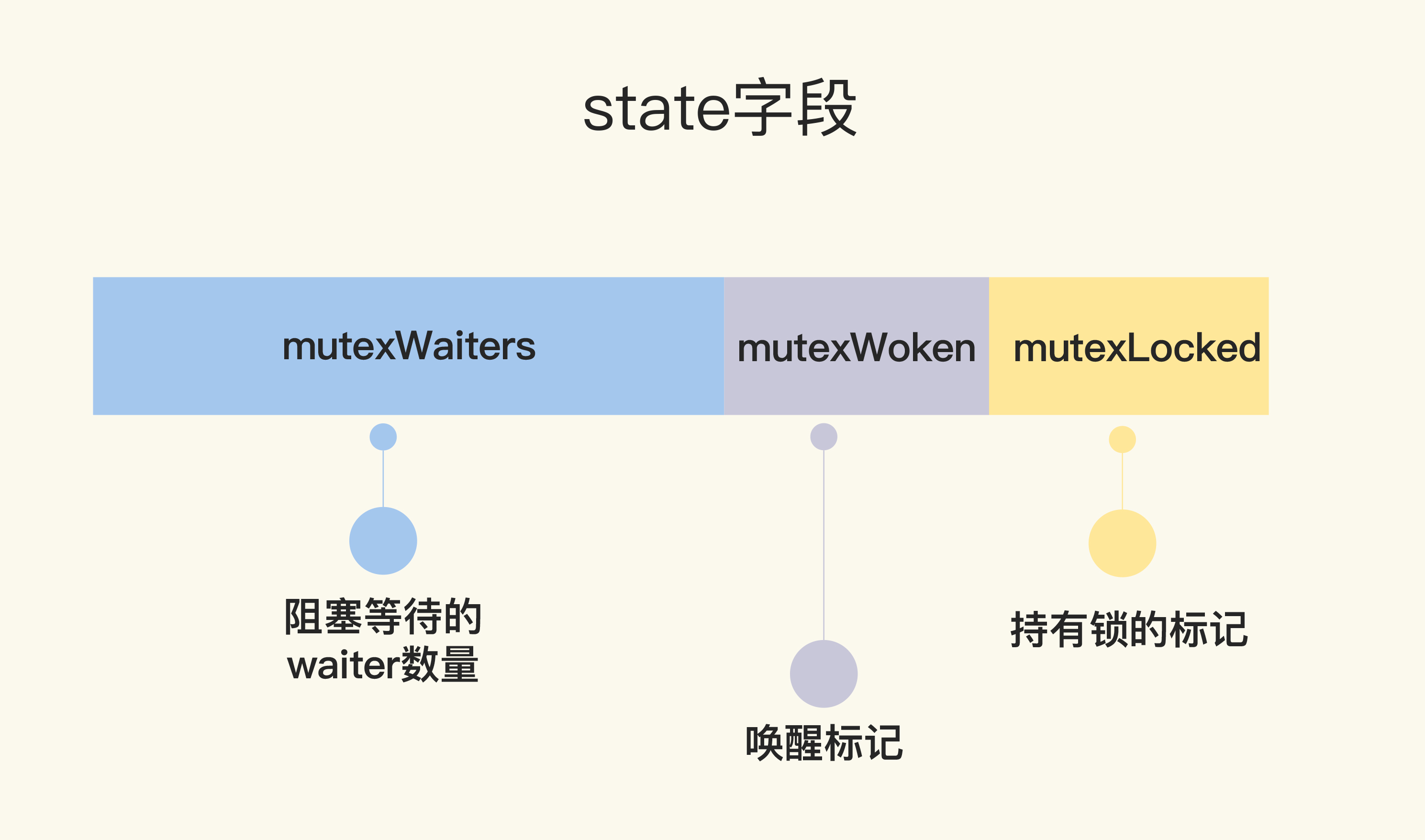
state 是一个复合型的字段,一个字段包含多个意义,这样可以通过尽可能少的内存来实现 互斥锁。
这个字段的第一位(最小的一位)来表示这个锁是否被持有,第二位代表是否有 唤醒的 goroutine,剩余的位数代表的是等待此锁的 goroutine 数。
1 |
|
如果想要获取锁的 goroutine 没有机会获取到锁,就会进行休眠,但是在 锁释放唤醒之后,它并不能像先前一样直接获取到锁,还是要和正在请求锁的 goroutine 进行争。这会给后来请求锁的 goroutine 一个机会,也让 CPU 中正在执行的 goroutine 有更多的机会获取到锁,在一定程度上提高了程序的性能。
1 | func (m *Mutex) Unlock() { |
相对于初版的设计,这次的改动主要就是,新来的 goroutine 也有机会先获取到锁,甚至 一个 goroutine 可能连续获取到锁,打破了先来先得的逻辑。但是,代码复杂度也显而易见。
互斥锁3.0:多给些机会
在 2015 年 2 月的改动中,如果新来的 goroutine 或者是被唤醒的 goroutine 首次获取不 到锁,它们就会通过自旋(runtime 中实现的)的方式,尝试检查锁是否被释放。在尝试一定的自旋次数后,再执行原来的逻辑。
1 | func (m *Mutex) Lock() { |
互斥锁4.0:解决饥饿
经过几次优化,Mutex 的代码越来越复杂,应对高并发争抢锁的场景也更加公平。但是你 有没有想过,因为新来的 goroutine 也参与竞争,有可能每次都会被新来的 goroutine 抢到获取锁的机会,在极端情况下,等待中的 goroutine 可能会一直获取不到锁,这就是饥饿问题。


1 | const ( |
跟之前的实现相比,当前的 Mutex 最重要的变化,就是增加饥饿模式。将饥饿模 式的最大等待时间阈值设置成了 1 毫秒,这就意味着,一旦等待者等待的时间超过了这个 阈值,Mutex 的处理就有可能进入饥饿模式,优先让等待者先获取到锁,新来的同学主动谦让一下,给老同志一些机会。
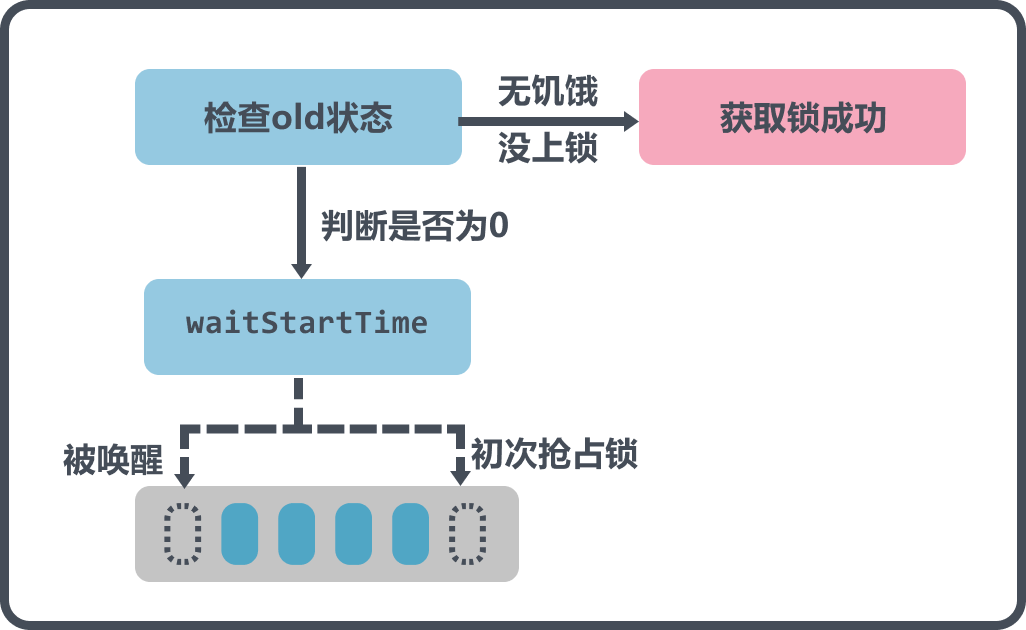
这部分的图解是休眠前的操作,休眠前会根据old的状态来判断能不能直接获取到锁,如果old状态没有上锁,也没有饥饿,那么直接break返回,因为这种情况会在CAS中设置加锁;
接着往下判断,waitStartTime是否等于0,如果不等于,说明不是第一次来了,而是被唤醒后来到这里,那么就不能直接放到队尾再休眠了,而是要放到队首,防止长时间抢不到锁.
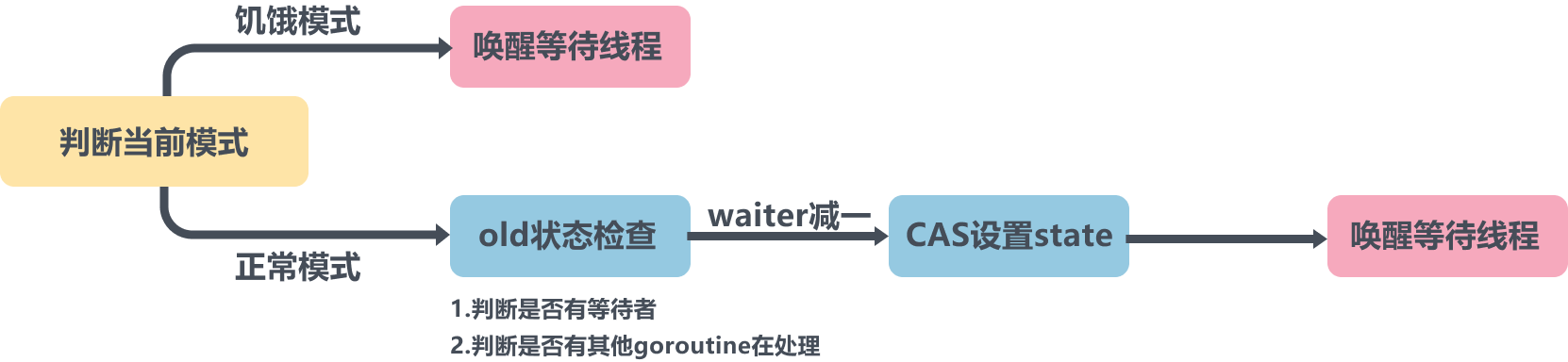
正常模式下,waiter 都是进入先入先出队列,被唤醒的 waiter 并不会直接持有锁,而是要 和新来的 goroutine 进行竞争。
在饥饿模式下,Mutex 的拥有者将直接把锁交给队列最前面的 waiter。新来的 goroutine 不会尝试获取锁,也不会 自旋,直接加入到等待队列的尾部。
扩展
TryLock
当一个 goroutine 调用这个 TryLock 方法请求锁的时候,如果这把锁没有被其他 goroutine 所持有,那么,这个 goroutine 就持有了这把锁,并返回 true;如果这把锁已经被其他 goroutine 所持有,或 者是正在准备交给某个被唤醒的 goroutine,那么,这个请求锁的 goroutine 就直接返回 false,不会阻塞在方法调用上。
1 | // 复制Mutex定义的常量 |
使用 Mutex 实现一个线程安全的队列
Mutex 经常会和其他非线程安全(对于 Go 来说,我们其实指的是 goroutine 安全)的数据结构一起,组合成一个线程安全的数据结构。新数据结构的业务逻辑由原来的数据结构提供,而 Mutex 提供了锁的机制,来保证线程安全。
1 | type SliceQueue struct { |
读写锁RWMutex
标准库中的 RWMutex 是一个 reader/writer 互斥锁。RWMutex 在某一时刻只能由任意数量的 reader 持有,或者是只被单个的 writer 持有。
实现原理
readers-writers 问题一般有三类,基于对读和写操作的优先级,读写锁的设计和实现也分成三类:
- Read-preferring:读优先的设计可以提供很高的并发性,但是,在竞争激烈的情况下 可能会导致写饥饿。这是因为,如果有大量的读,这种设计会导致只有所有的读都释放 了锁之后,写才可能获取到锁。
- Write-preferring:写优先的设计意味着,如果已经有一个 writer 在等待请求锁的 话,它会阻止新来的请求锁的 reader 获取到锁,所以优先保障 writer。
- 不指定优先级:不区分 reader 和 writer 优先级,某些场景下这种不指定优先级的设计反而更有效,因为第一类优先级会导致写饥饿,第二类优先级可能会导致读饥饿,这种不指定优先级的访问不再区分读写,大家都是同一个优先级,解决了饥饿的问题。
Go 标准库中的 RWMutex 是基于 Mutex 实现的,设计是 Write-preferring 方案。一个正在阻塞的 Lock 调用会排除新的 reader 请求到锁。
RLock/RUnlock 的实现
1 | type RWMutex struct { |
Lock
1 |
|
Unlock
1 | func (rw *RWMutex) Unlock() { |
WaitGroup
WaitGroup 很简单,就是 package sync 用来做任务编排的一个并发原语。它要解决的就是并发 - 等待的问题: 现在有一个 goroutine A 在检查点(checkpoint)等待一组 goroutine 全部完成,如果 在执行任务的这些 goroutine 还没全部完成,那么 goroutine A 就会阻塞在检查点,直到 所有 goroutine 都完成后才能继续执行。
实现原理
1 | type WaitGroup struct { |
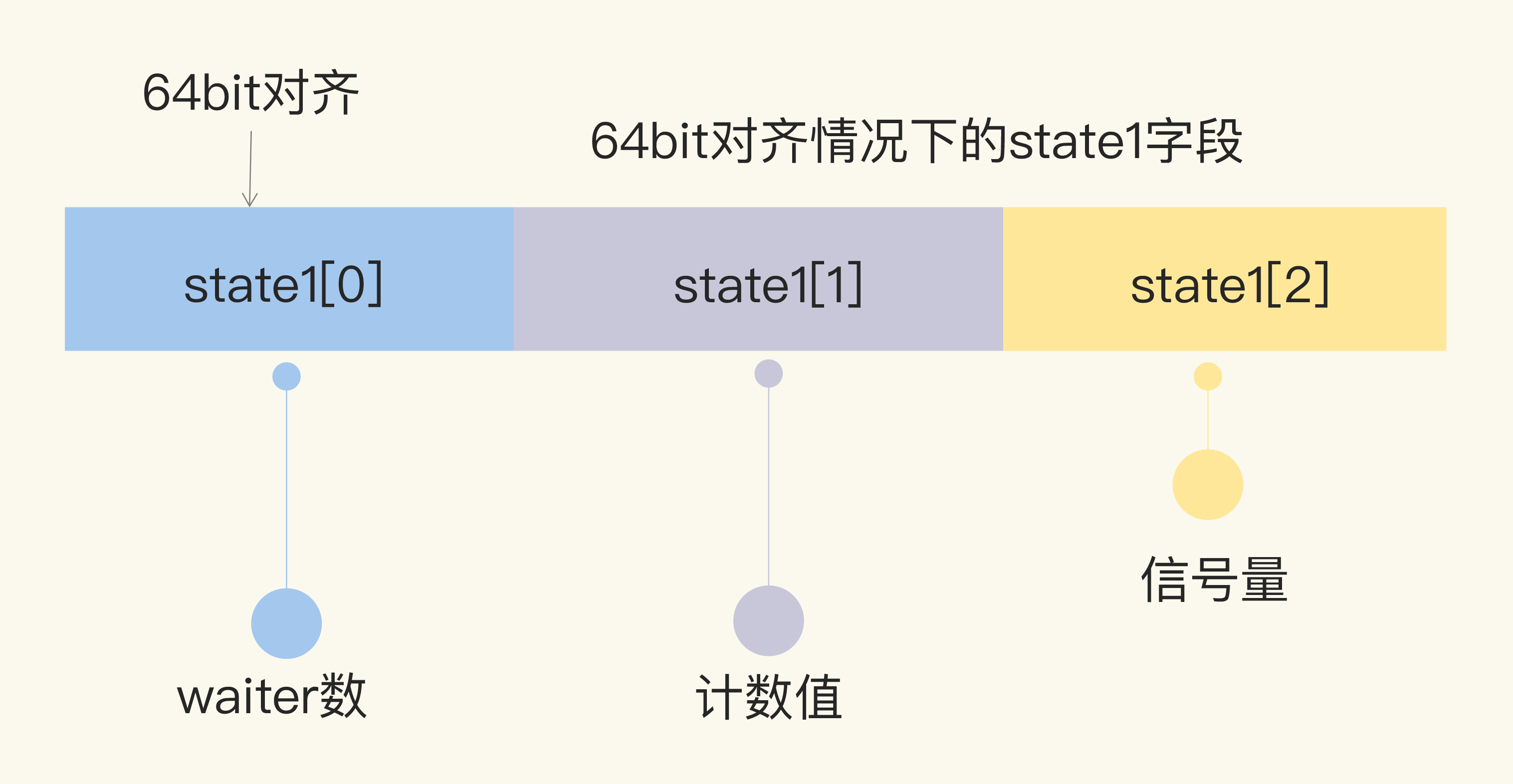
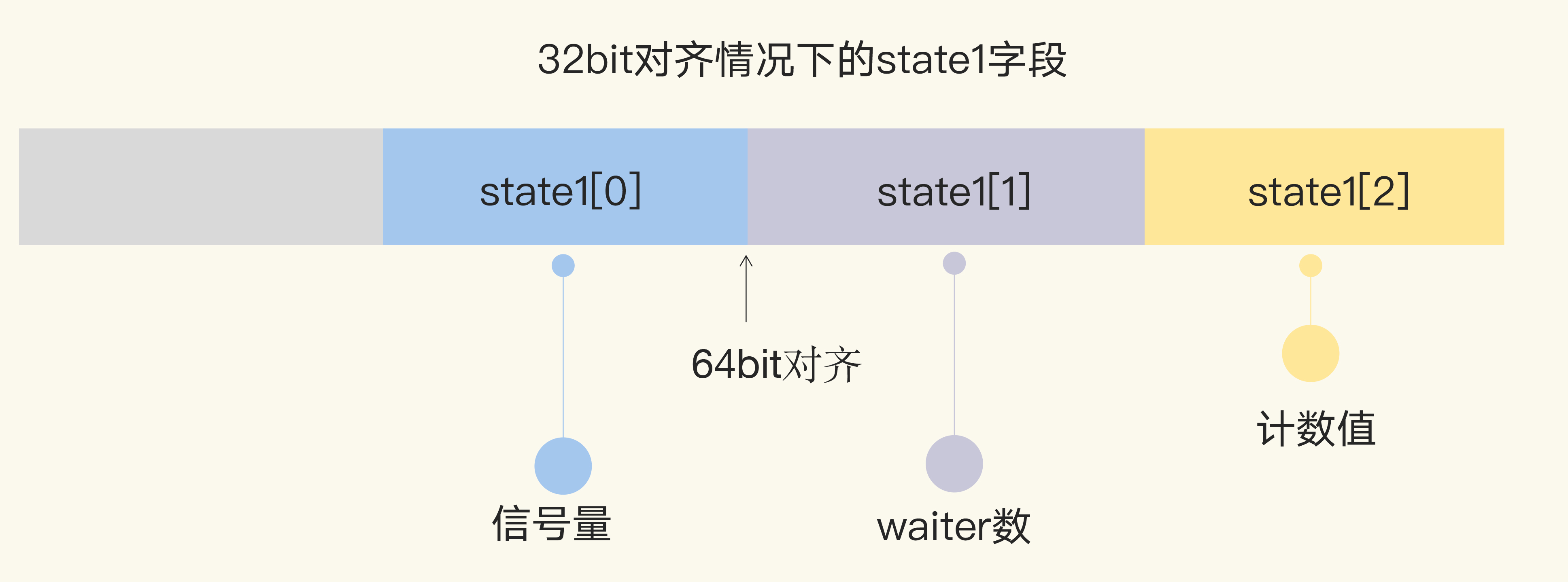
Add
1 | func (wg *WaitGroup) Add(delta int) { |
Wait
1 |
|

