在分布式场景下,很多时候我们需要保证数据的唯一性,所以我们需要生成全局唯一的id,对数据进行标识。
在选择方案前,我们先来对我们的需求进行梳理。
一、需求
下面我们来列举下我们可能的需求。
- 全局唯一性
- 高可用
- 高性能
- 所占空间尽可能小
- 部分场景下的递增(趋势递增、绝对递增)
有了已上需求,我们来分析现有大家常用的解决方案。
二、常见解决方案
UUID & GUID
uuid与guid本质是相同的,只是guid来源于微软。一个uuid是一个16字节(128bit)的数字。通常一个uuid表示为32个16进制数字。
uuid本质上包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素进行生成。在特定的范围内可保证唯一性。
优点
- 在特定场景下生成,保证唯一性。
- 生成方便,单机即可生成,无需统一管理。
缺点
- 但是uuid所占空间较大,128Bit并不适合成为数据库主键。
- 作为数据库主键,在InnoDB引擎下,uuid的无序性可能会引发数据位置频繁变动,严重影响性能。
基于DB自增单点以及多节点方案
基于DB自增进行id生成,同样也是最常见的解决方案,单点实现方案不用多说,多主模式下,为了防止产生相同ID,可以设定起点与步长。
如下图所示,是一个非常简单的两个DB节点的模型。
优点
- 实现成本低,直接利用DB原有的功能进行实现。
- 可以实现单调递增,对递增有需求的场景十分友好。
缺点
- 在单点或者读写分离场景下,只有一个库可进行生成,故障风险高,不满足高可用。
- 多节点情况下,性能到达峰值,扩展难度较高。
- 涉及DB迁移,合并,分库分表,都会有各种问题。
基于DB的号段模式
号段模式本质上是DB自增方案的优化,可以理解为由原来的从DB中单条获取id,变为批量获取并缓存至本地,增加速度,降低DB压力。
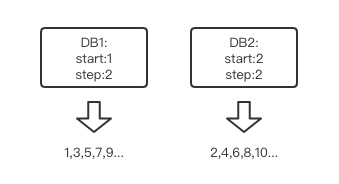
一般来说我们会实现一个IdGen服务来控制id的单条发放至业务应用。
并且,为了高可用,IdGen服务应该是一个集群,业务应用获取Id时应由VPS随机的选择某个节点。简单示意图如下图所示。
在DB中,我们需要建立一个表。用来进行号段的获取。
1 | CREATE TABLE IdGen ( |
tag表示业务名,在同一个业务中,保证id唯一,max_id为当前业务最大id为多少,step表示当前步长(一次获取Id的数量)。
同样,我们可以通过一个事务来获取一段id:
1 | Begin |
优化点
1. 双buffer优化
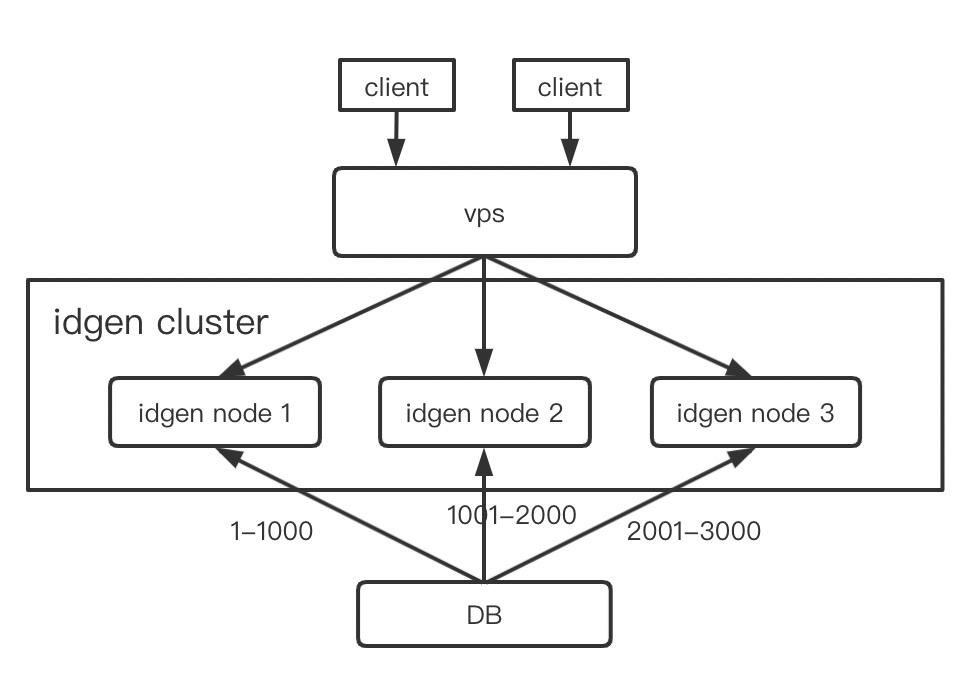
在上面的实现中,有两个问题需要注意。在任意节点的号段耗尽时,id的生成需要等待从DB中取回下个号段后继续进行。所以,id的下发在每次切换号段时都会有一定延迟。其次,在切换号段时如果网络抖动,或出现慢查询,甚至于连接出现问题,都无法正常运作,这是我们无法接受的。
所以我们可以同时缓存两个号段,防止出现这样的问题。当前正在使用的号段使用超过某个阈值(10%)时,使用异步的方式更新下一个号段。
2. 动态步长
一个号段的使用时间是由号段的下发速度以及号段长度来决定的,为了高可用的保证,我们希望在db短时间内不可用的情况下,仍然可以维持我们的发号器正常运转。我们可以通过增加号段的长度来实现。但是号段过长的话。服务的重启必然会导致大规模的空洞现象(大量id由于服务重启被丢弃)。所以有一个很好的选择是根据下发速度来决定下次获取号段的步长。
在速度基本保持稳定的状态下,这样就可以在稳定性与防止号段空洞之间做出很好的平衡。
优点
- 当前的id生成器横向扩张能力很强。性能不在是问题。
- 生成的id为可以是64位长整型,使用十分方便。
- 趋势递增,并且生成的id最大值在DB中有记录(max_id),服务的迁移相对容易。
缺点
- 虽然对DB依赖较弱,但在DB长时间宕机情况下仍会不可用。
- ID连续,不够随机,订单数量等敏感信息有可能泄露。
snowflake模式
snowflake算法是Twitter开源的分布式ID生成算法,生成的id是一个64bit长整型数字。和UUID类似,snowflake算法同样是通过划分数字bit位功能。具体如下图。
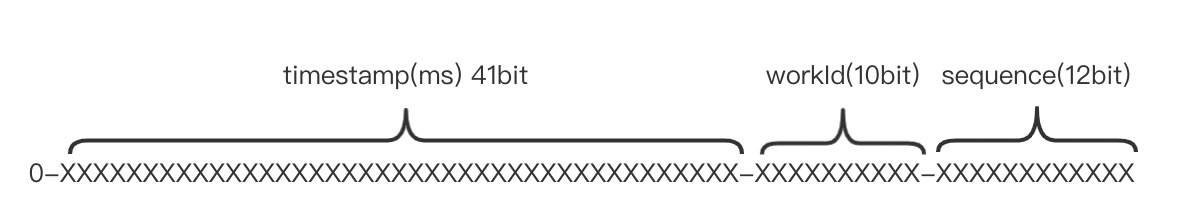
毫秒级时间戳41bit,最多可用69年左右。workId10bit,最多支持部署1024个节点。自增序列长12bit,也就是在每一毫秒内,同一个节点最多支持生成4096个不同的id。由于多数情况下,我们都会把64位长整型数字的首位作为符号位,所以选择将符号位弃置。这样,理论上最多一秒可以生成**1000(ms)*1024(节点)*4096(自增序列)**,基本上可以满足绝大多数场景下的需求。
魔改与优化
时间控制
由于snowflake强依赖时间戳,需要注意以下问题。
- 时钟回拨问题。
- 多节点之间时间同步问题。
一般来说,短步长的时钟回拨,可以直接等待按照上次时间等待下一个时间段到来,而对于长步长的时钟回拨。直接异常也是比较好的选择。除此之外,也有更优雅的一些办法,如增加1~2个bit的回拨位,发生时钟回拨后,将回拨位+1,两个bit在发生4次时钟回后才会归位。发生冲突的概率近乎不存在。
同样,在多节点部署时,还需要更多的考虑到workid是否需要复用?如果节点时间不同步,新拉起的服务复用了之前已经挂掉的旧节点的workid,但是机器时间却小于旧的节点,则有可能出现id重复。在集群部署中,除了集群本身的需要考虑进行时间同步外,本身id生成服务在启动时也可以考虑进行节点之间的时间check,以及定时上报机器时间。
针对特定业务场景优化
在特定业务场景中,标准的雪花模式可能并不是最优选择,可根据需求对各个区间段进行调整。example
与js进行交互
在业务场景中,易于js进行交互,可以考虑31bit的秒级时间戳,5bit的workId,以及16bit的自增序列。这样只用到53bit,与js交互不会有精度损失。32节点,每秒可以生成6.5万左右的id。时间戳耗尽也需要百年已上。在某些条件下也是比较好的选择。
考虑可配置
如果业务众多并不能决定,在确定节点规模后,对于自增id段以及时间戳段也可以做成可配置,提供默认方案的同时,也可以在在不同环境下使用不同分配方案,让id生成变得更加灵活与方便。
时间的缓存与借取
如果峰值QPS过高,超过了对应时间的自增上限怎么办?等待是一种解决方案,当然我们也可以考虑向前”借用”时间,直接向前递增时间戳,而并不是等待。而这种方案带来的问题就是,时间戳段耗尽可能更加提前到来。并且,时间戳的生成与真实时间无关。节点的重启,也同样可能需要重新思考。
优点
- 可以不依赖任何其他中间件。
- 节点在workId范围内进行扩容缩容十分便捷。
- 生成的id同样为64bit长整型数字,并且随时间戳趋势递增,使用十分便捷。
缺点
- 强依赖时间戳,需要考虑多节点时间同步以及时钟回拨问题。
我们的方案
在此之前,公司原有的id生成功能被整合在了公司的微服务框架中,使用的是类雪花算法,由41bit毫秒级时间戳,10bit的workid,以及1位的自增序列组成。workid是由服务发现时对应的序号自动生成的,可以保证在每一个独立的服务下的不同节点的workid不同。但是原先的方案中也存在许多问题。
- 不同服务之间生成的id无法保证不冲突。在某些使用场景下,不同服务使用同一套id的场景也同样常见。
- 缺少应有的时间校验机制,在极端情况下可能出现id重复现象。
- 每毫秒仅可生成2个id,在高并发压力下,服务可能会由于id生成量限制而导致服务本身收到影响。
由于上述问题,以及公司的后端服务均为golang,并且go语言并没有比较成熟的分布式高可用id生成器实现方案。所以我们决定在现有的算法中进行选择,实现我们自己的的id生成器。在上述各种实现方案中,稳定性、扩展性与易用性最好的应该是类snowflake模式与号段模式。其他的方案或多或少均有一些比较严重的短板。
新的id生成服务基本上解决了之前的问题,并且在一定程度上进行兼容。保留了老的id生成方式,方便一些旧的服务进行迁移。
workId生成、以及雪花模式的时间同步等逻辑均使用的etcd集群进行管理。在雪花模式中,考虑到workId复用在实现上要尽可能简单,所以禁止了时间提前借取,防止在重启时出现id重复的问题。考虑到不同业务方需求可能不尽相同,雪花模式有两种默认配置,分别支持标准雪花模式(标准63bit)以及兼容js的slowid模式(53bit)。当然,除了默认配置,针对特殊的一些需求,也开放了全自定义模式,可以允许大家进行手动配置。
结语
在最后,放上一个完整版的的id生成器实现方案的思维导图。